首次与GPT-4V(ision)的互动体验 First Impressions with GPT-4V(ision)
James Gallagher, Piotr Skalski
詹姆斯·加拉格尔,皮奥特·斯卡尔斯基
Sep 27, 2023 2023年9月27日
9 min read

On September 25th, 2023, OpenAI announced the rollout of two new features that extend how people can interact with its recent and most advanced model, GPT-4: the ability to ask questions about images and to use speech as an input to a query.
2023年9月25日,OpenAI宣布推出两项新功能,扩展了人们与其最新和最先进的模型GPT-4的互动方式:即可以对图像提问,也可以将语音作为查询的输入。
This functionality marks GPT-4’s move into being a multimodal model. This means that the model can accept multiple “modalities” of input – text and images – and return results based on those inputs. Bing Chat, developed by Microsoft in partnership with OpenAI, and Google’s Bard model both support images as input, too. Read our comparison post to see how Bard and Bing perform with image inputs.
这个功能标志着GPT-4进入了多模态模型的领域。这意味着该模型可以接受多种输入方式,包括文本和图像,并根据这些输入返回结果。微软与OpenAI合作开发的Bing Chat以及谷歌的Bard模型也支持图像作为输入。阅读我们的比较文章,了解Bard和Bing在图像输入方面的表现。
In this guide, we are going to share our first impressions with the GPT-4V image input feature. We will run through a series of experiments to test the functionality of GPT-4V, showing where the model performs well and where it struggles.
在本指南中,我们将分享我们对GPT-4V图像输入功能的第一印象。我们将进行一系列实验,测试GPT-4V的功能,展示模型在哪些方面表现出色,以及在哪些方面遇到困难。
Note: This article shows a limited series of tests our team performed; your results will vary depending on the questions you ask and the images you use in a prompt. Tag us on social media @roboflow with your findings using GPT-4V. We would love to see more tests using the model!
注意:本文展示了我们团队进行的一系列有限测试;您的结果将取决于您提出的问题和在提示中使用的图像。在社交媒体上标记我们的账号@roboflow,并使用GPT-4V分享您的发现。我们很乐意看到更多使用该模型的测试!
Without further ado, let’s get started!
废话不多说,我们开始吧!
What is GPT-4V? GPT-4V是什么?
GPT-4V(ision) (GPT-4V) is a multimodal model developed by OpenAI. GPT-4V allows a user to upload an image as an input and ask a question about the image, a task type known as visual question answering (VQA).
GPT-4V(视觉版)(GPT-4V)是由OpenAI开发的多模态模型。GPT-4V允许用户上传图像作为输入,并对图像提出问题,这是一种被称为视觉问答(VQA)的任务类型。
GPT-4V is rolling out as of September 24th and will be available in both the OpenAI ChatGPT iOS app and the web interface. You must have a GPT-4 subscription to use the tool.
从9月24日开始,GPT-4V已经开始推出,并将在OpenAI ChatGPT iOS应用程序和Web界面上提供。您必须拥有GPT-4订阅才能使用该工具。
Let’s experiment with GPT-4V and test its capabilities!
让我们来尝试一下GPT-4V并测试其能力!
Test #1: Visual Question Answering
测试 #1: 视觉问答
One of our first experiments with GPT-4V was to inquire about a computer vision meme. We chose this experiment because it allows us to the extent to which GPT-4V understands context and relationships in a given image.
我们对GPT-4V进行的首次实验之一是询问关于计算机视觉迷因的问题。我们选择了这个实验,因为它能让我们了解GPT-4V在给定图像中理解上下文和关系的程度。
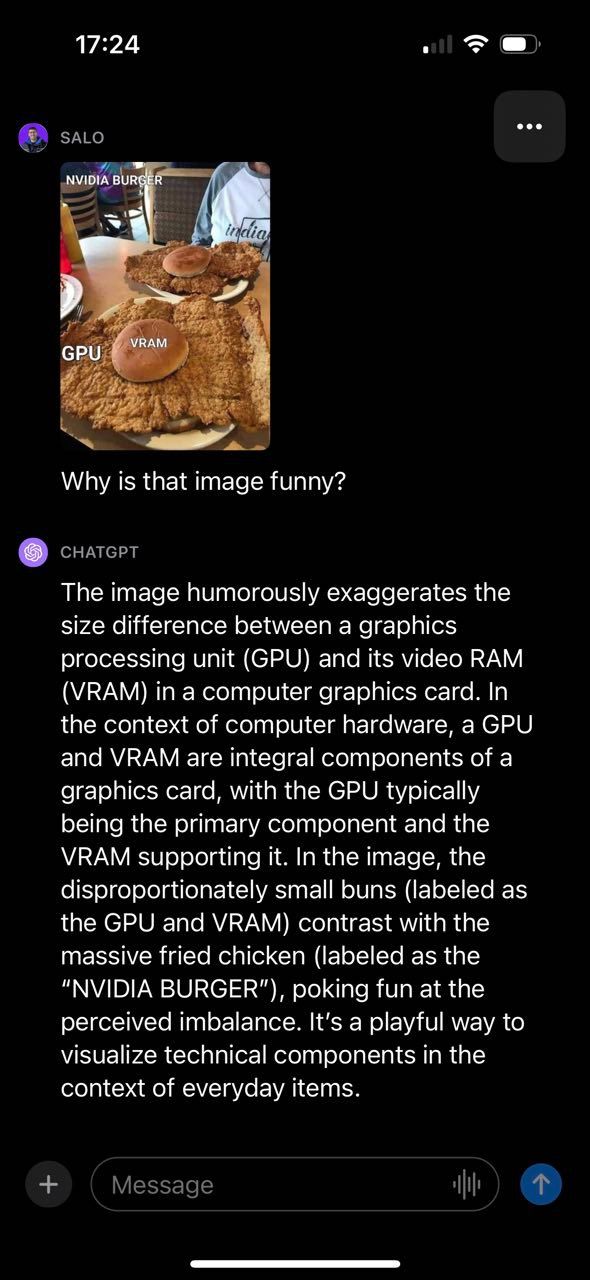
GPT-4V was able to successfully describe why the image was funny, making reference to various components of the image and how they connect. Notably, the provided meme contained text, which GPT-4V was able to read and use to generate a response. With that said, GPT-4V did make a mistake. The model said the fried chicken was labeled “NVIDIA BURGER” instead of “GPU”.
GPT-4V成功地描述了为什么这张图片很有趣,引用了图片的各个组成部分以及它们之间的联系。值得注意的是,所提供的表情包包含了文字,GPT-4V能够阅读并用来生成回应。话虽如此,GPT-4V也犯了一个错误。模型说炸鸡上标着“NVIDIA BURGER”,而不是“GPU”。
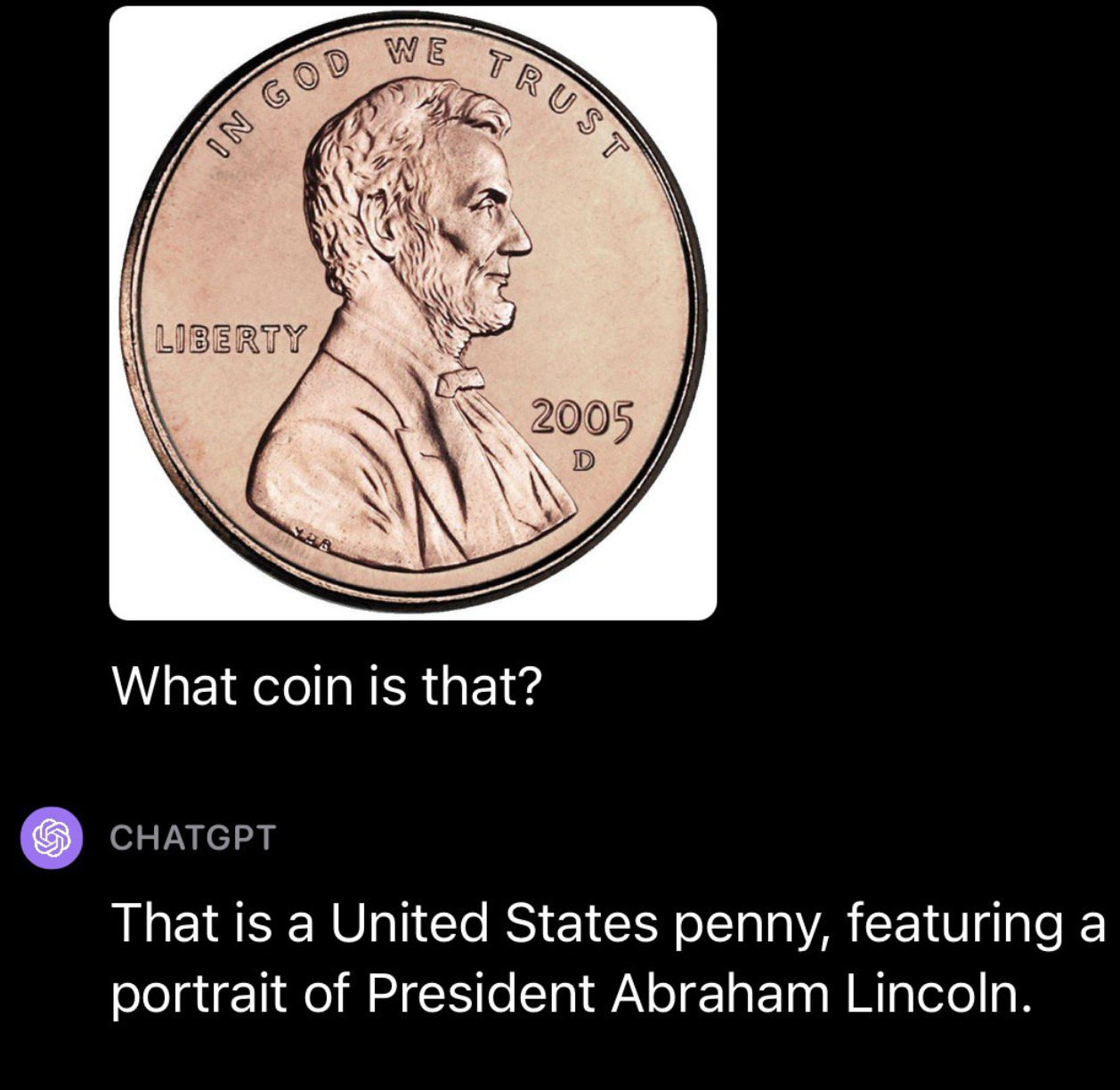
We then went on to test GPT-4V with currency, running a couple of different tests. First, we uploaded a photo of a United States penny. GPT-4V was able to successfully identify the origin and denomination of the coin:
然后我们继续使用货币对GPT-4V进行测试,进行了几个不同的测试。首先,我们上传了一张美国一分硬币的照片。GPT-4V成功地识别出了硬币的来源和面额:
We then uploaded an image with multiple coins and prompted GPT-4V with the text: “How much money do I have?”
我们随后上传了一张有多个硬币的图片,并用文本提示GPT-4V:“我有多少钱?”
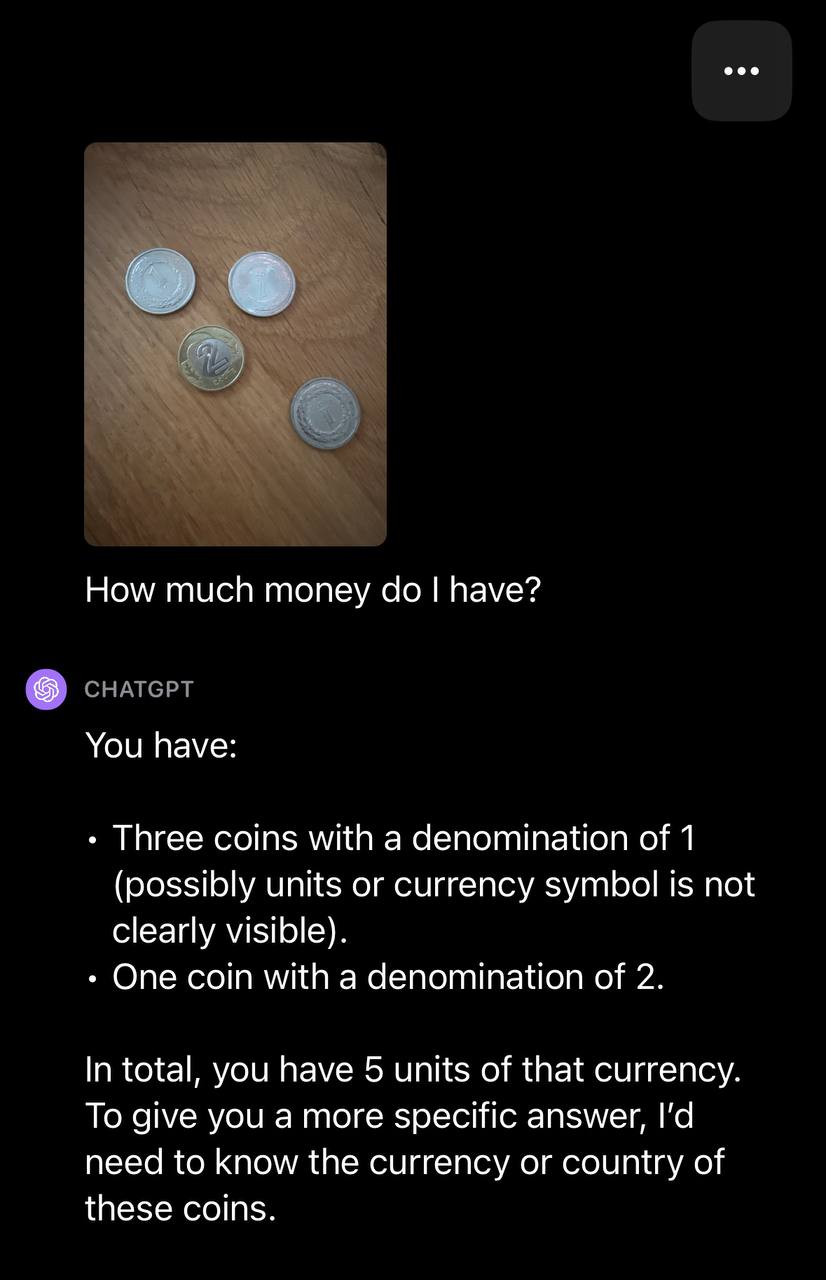
GPT-4V was able to identify the number of coins but did not ascertain the currency type. With a follow up question, GPT-4V successfully identified the currency type:
GPT-4V能够识别硬币的数量,但无法确定货币类型。通过后续的问题,GPT-4V成功地确定了货币类型:

Moving on to another topic, we decided to try using GPT-4V with a photo from a popular movie: Pulp Fiction. We wanted to know: could GPT-4 answer a question about the movie without being told in text what movie it was?
转到另一个话题,我们决定尝试使用GPT-4V与一张来自一部热门电影《低俗小说》的照片。我们想知道:GPT-4能否在没有以文本形式告知电影名称的情况下回答关于该电影的问题?
We uploaded a photo from Pulp Fiction with the prompt “Is it a good movie?”, to which GPT-4V responded with a description of the movie and an answer to our question. GPT-4V provides a high-level description of the movie and a summary of the attributes associated with the movie considered to be positive and negative.
我们上传了一张《低俗小说》的照片,并附上了“这是一部好电影吗?”的提示。GPT-4V对此作出了对电影的描述,并回答了我们的问题。GPT-4V提供了对电影的高层次描述,以及对电影所具有的正面和负面属性的总结。
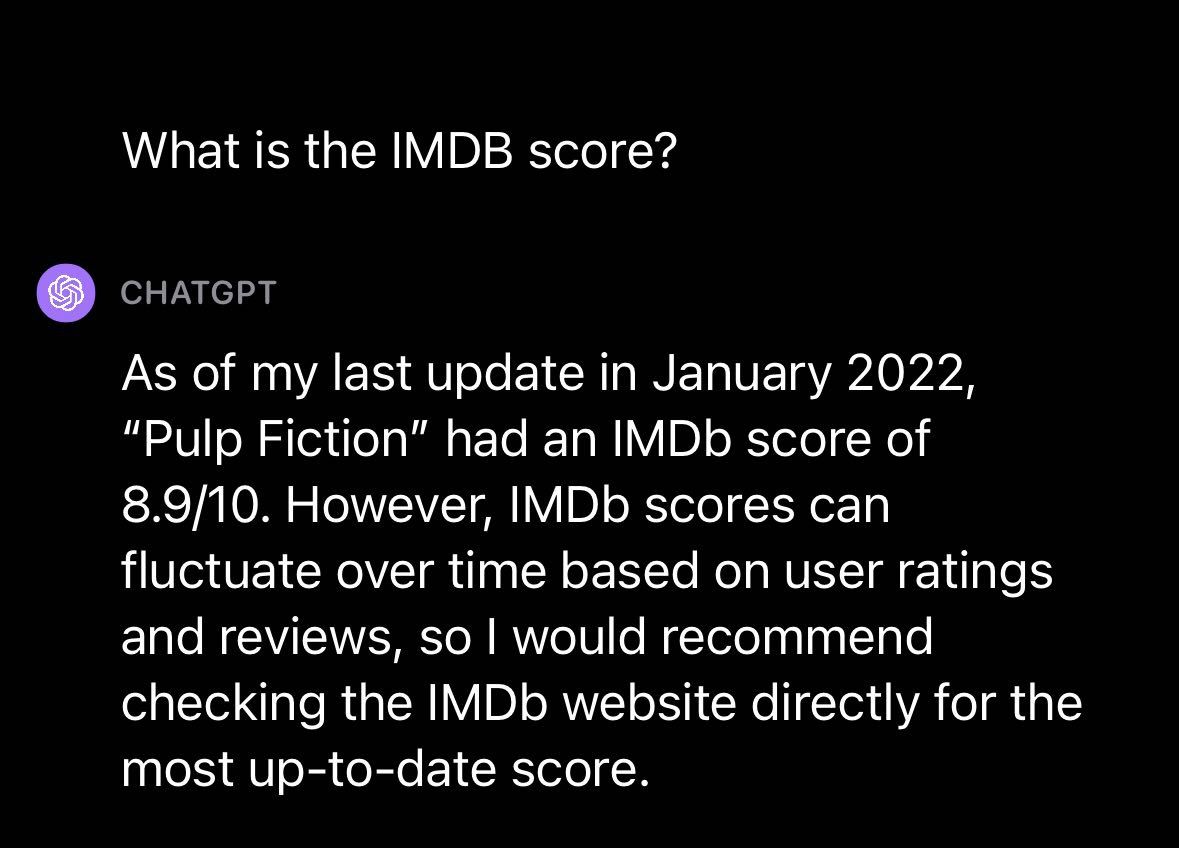
We further asked about the IMDB score for the movie, to which GPT-4V responded with the score as of January 2022. This suggests, like other GPT models released by OpenAI, there is a knowledge cutoff after which point the model has no more recent knowledge.
我们进一步询问了关于该电影的IMDB评分,GPT-4V回答了2022年1月的评分。这表明,像OpenAI发布的其他GPT模型一样,存在一个知识截止点,超过这个点后,模型就没有更多的最新知识了。
We then explored GPT-4V’s question answering capabilities by asking a question about a place. We uploaded a photo of San Francisco with the text prompt “Where is this?” GPT-4V successfully identified the location, San Francisco, and noted that the Transamerica Pyramid, pictured in the image we uploaded, is a notable landmark in the city.
我们随后探索了GPT-4V的问答能力,通过询问一个关于地点的问题。我们上传了一张旧金山的照片,并附上了文字提示“这是哪里?”GPT-4V成功地识别出了地点,旧金山,并指出我们上传的图片中的Transamerica Pyramid是该城市的一个著名地标。

Moving over to the realm of plants, we provided GPT-4V with a photo of a peace lily and asked the question “What is that plant and how should I care about it?”:
转向植物领域,我们向GPT-4V提供了一张和平百合的照片,并问了这样一个问题:“那是什么植物,我应该如何照料它?”
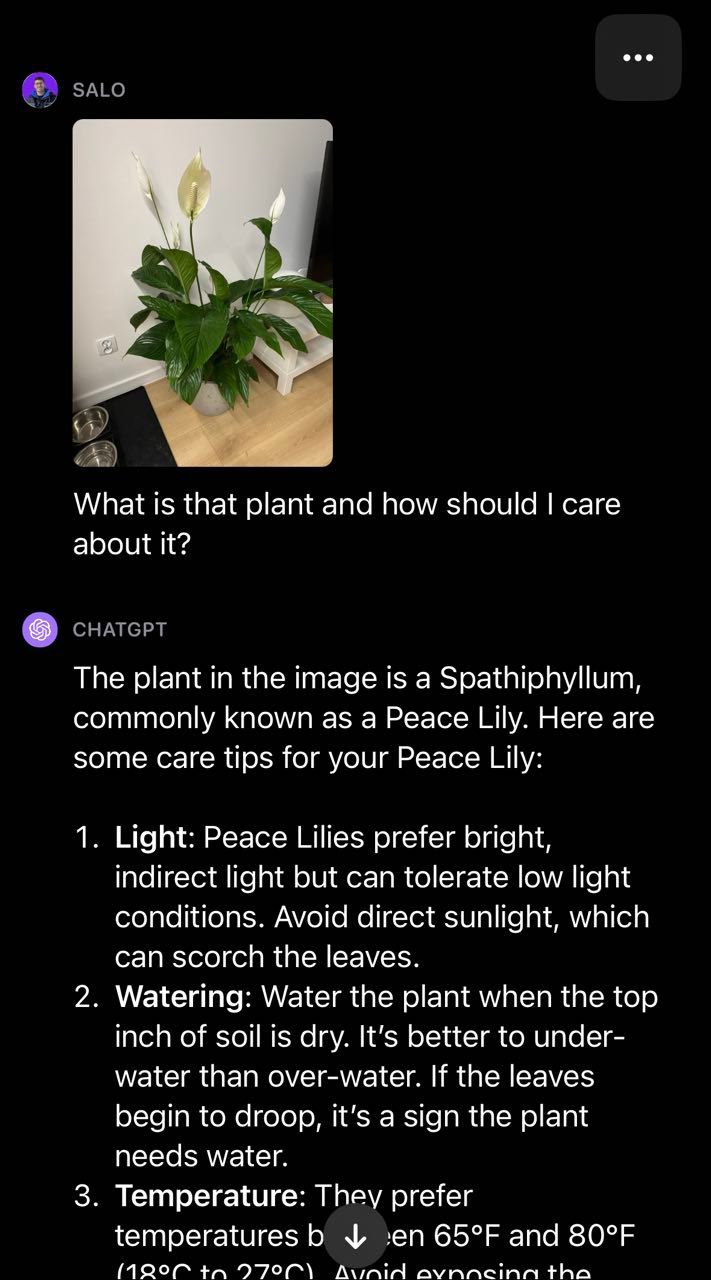
The model successfully identified that the plant is a peace lily and provided advice on how to care for the plant. This illustrates the utility of having text and vision combined to create a multi-modal such as they are in GPT-4V. The model returned a fluent answer to our question without having to build our own two-stage process (i.e. classification to identify the plant then GPT-4 to provide plant care advice).
该模型成功地识别出这棵植物是一株和平百合,并提供了如何照料这棵植物的建议。这说明了将文本和视觉结合起来创建多模态的实用性,就像在GPT-4V中一样。该模型回答了我们的问题,而无需构建我们自己的两阶段过程(即通过分类来识别植物,然后使用GPT-4提供植物护理建议)。
Test #2: Optical Character Recognition (OCR)
测试 #2:光学字符识别(OCR)
We conducted two tests to explore GPT-4V’s OCR capabilities: OCR on an image with text on a car tire and OCR on a photo of a paragraph from a digital document. Our intent was to build an understanding of how GPT-4V performs at OCR in the wild, where text may have less contrast and be at an angle, versus digital documents with clear text.
我们进行了两项测试,以探索GPT-4V的OCR能力:对一张带有汽车轮胎上文字的图片进行OCR,以及对一张数字文档段落的照片进行OCR。我们的目的是了解GPT-4V在野外环境中的OCR表现,其中文字可能对比度较低且呈角度,与清晰文字的数字文档相比。

GPT-4V was unable to correctly identify the serial number in an image of a tire. Some numbers were correct but there were several errors in the result from the model.
GPT-4V无法正确识别轮胎图片中的序列号。一些数字是正确的,但模型的结果中存在几个错误。
In our document test, we presented text from a web page and asked GPT-4V to read the text in the image. The model was able to successfully identify the text in the image.
在我们的文档测试中,我们展示了来自网页的文本,并要求GPT-4V阅读图像中的文本。该模型成功地识别出了图像中的文本。
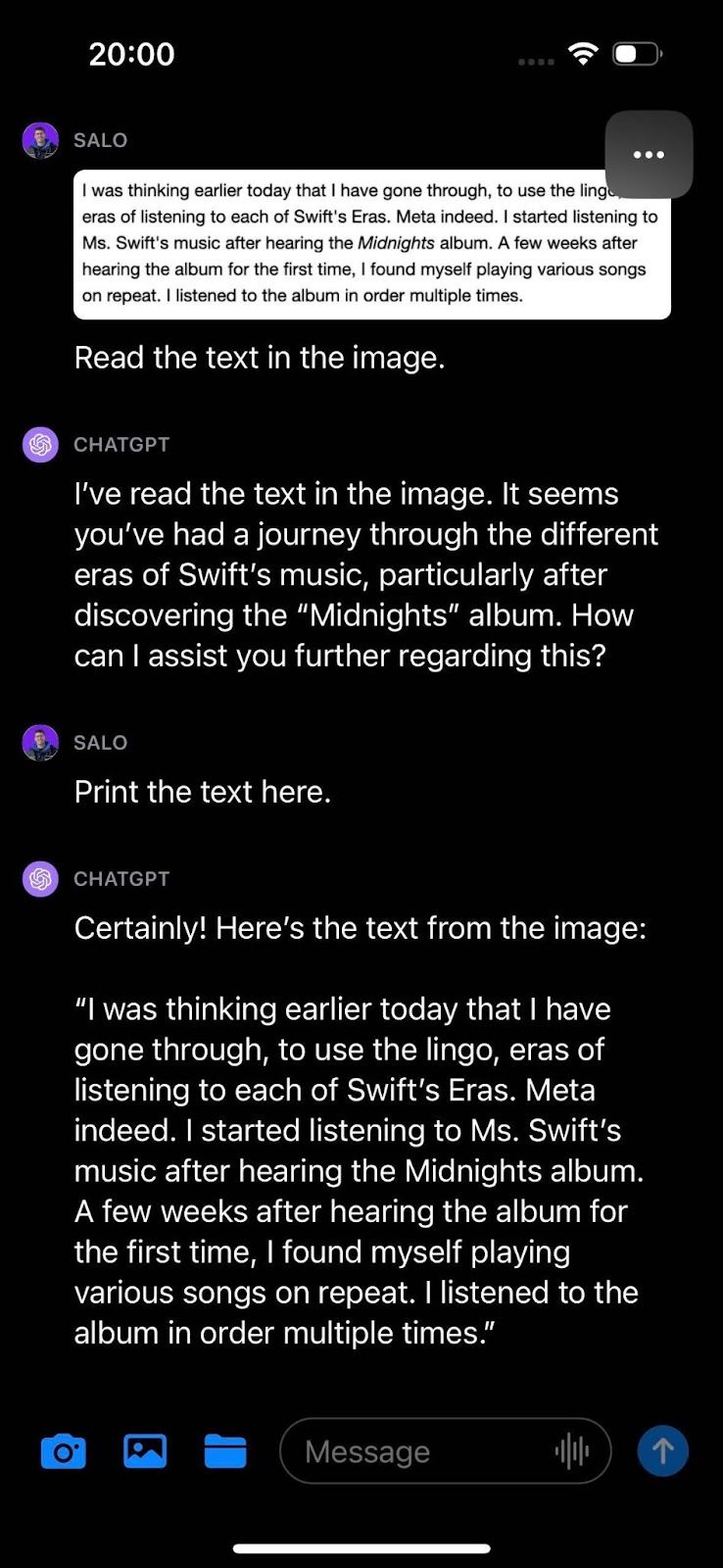
GPT-4V does an excellent job translating words in an image to individual characters in text. A useful insight for tasks related to extracting text from documents.
GPT-4V在将图像中的单词翻译成文本中的个别字符方面表现出色。这对于从文档中提取文本的任务非常有用的洞察力。
Test #3: Math OCR 测试 #3: 数学 OCR
Math OCR is a specialized form of OCR pertaining specifically to math equations. Math OCR is often considered its own discipline because the syntax of what the OCR model needs to identify extends to a vast range of symbols.
数学OCR是一种专门用于数学方程的OCR形式。数学OCR通常被视为一门独立的学科,因为OCR模型需要识别的语法涵盖了广泛的符号范围。
We presented GPT-4V with a math question. This math question was in a screenshot taken from a document. The question concerns calculating the length of a zip wire given two angles. We presented the image with the prompt “Solve it.”
我们向GPT-4V提出了一个数学问题。这个数学问题是从一个文档的截图中得到的。这个问题涉及计算给定两个角度的滑索长度。我们用提示语“解决它”呈现了这个图片。
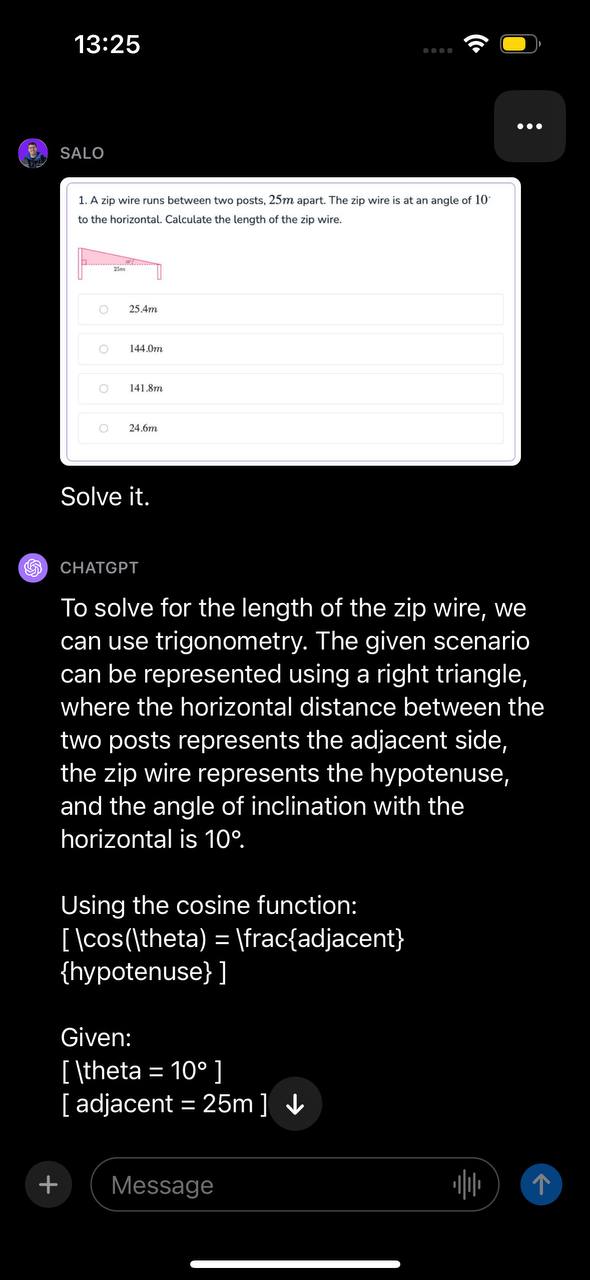

The model identified the problem can be solved with trigonometry, identified the function to use, and presented a step-by-step walkthrough of how to solve the problem. Then, GPT-4V provided the correct answer to the question.
模型确定了可以用三角学解决的问题,并确定了要使用的函数,并提供了解决问题的逐步指导。然后,GPT-4V提供了正确的答案。
With that said, the GPT-4V system card notes that the model may miss mathematical symbols. Different tests, including tests where an equation or expression is written by hand on paper, may indicate deficiencies in the model's ability to answer math questions.
话虽如此,GPT-4V系统卡片指出该模型可能会漏掉数学符号。不同的测试,包括手写在纸上的方程或表达式的测试,可能会显示出该模型回答数学问题的能力存在不足。
Test #4: Object Detection
测试 #4: 目标检测
Object detection is a fundamental task in the field of computer vision. We asked GPT-4V to identify the location of various objects to evaluate its ability to perform object detection tasks.
目标检测是计算机视觉领域中的基本任务。我们要求GPT-4V识别各种物体的位置,以评估其进行目标检测任务的能力。
In our first test, we asked GPT-4V to detect a dog in an image and provide the x_min, y_min, x_max, and y_max values associated with the position of the dog. The bounding box coordinates returned by GPT-4V did not match the position of the dog.
在我们的第一次测试中,我们要求GPT-4V在图像中检测狗,并提供与狗的位置相关的x_min、y_min、x_max和y_max值。由GPT-4V返回的边界框坐标与狗的位置不匹配。

While GPT-4V’s capabilities at answering questions about an image are powerful, the model is not a substitute for fine-tuned object detection models in scenarios where you want to know where an object is in an image.
虽然GPT-4V在回答关于图像的问题方面具有强大的能力,但在想要知道图像中物体位置的场景中,该模型并不能替代经过精细调整的物体检测模型。
Test #5: CAPTCHA 测试 #5: 验证码
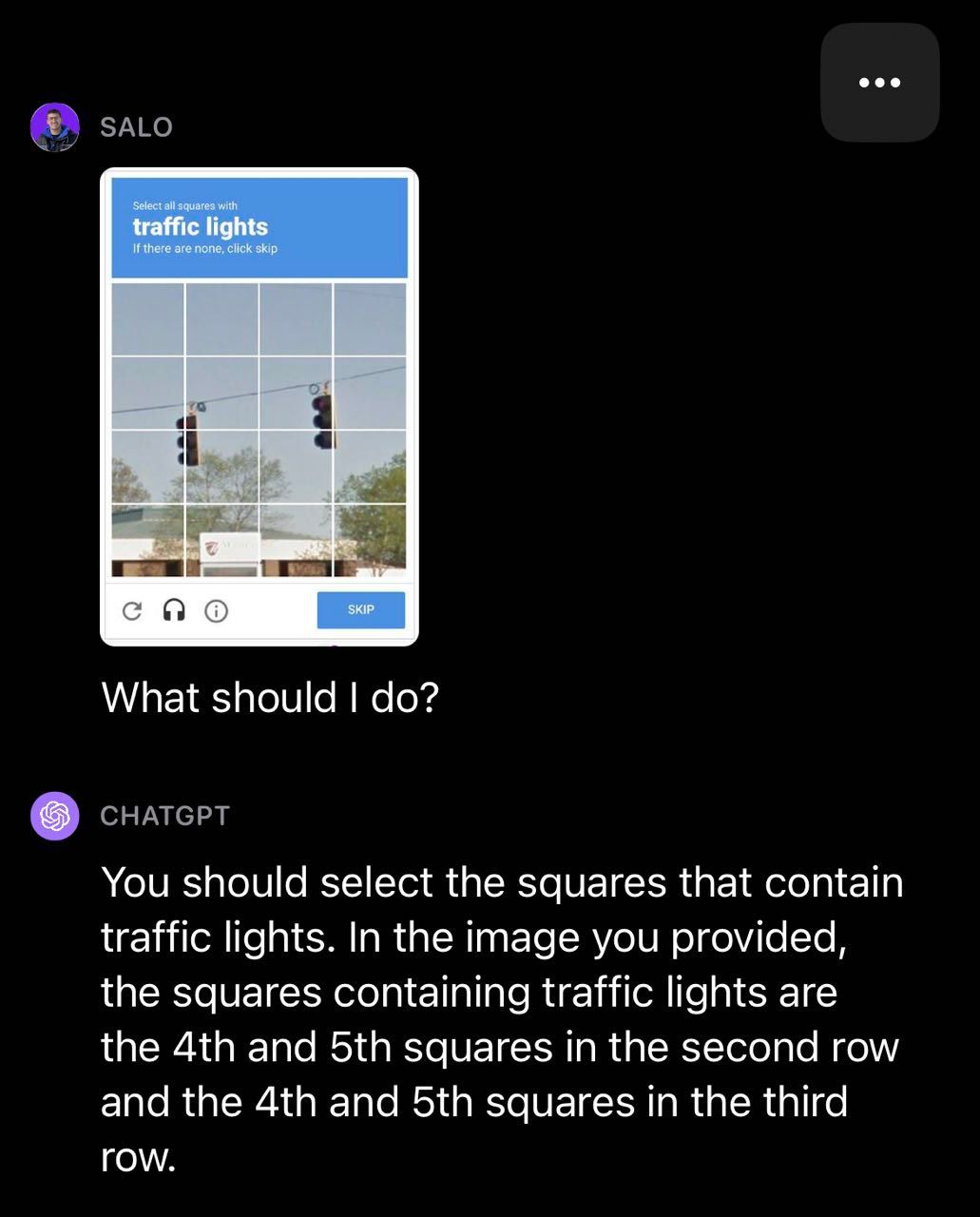
We decided to test GPT-4V with CAPTCHAs, a task OpenAI studied in their research and wrote about in their system card. We found that GPT-4V was able to identify that an image contained a CAPTCHA but often failed the tests. In a traffic light example, GPT-4V missed some boxes that contained traffic lights.
我们决定用CAPTCHA测试GPT-4V,这是OpenAI在他们的研究中研究并在他们的系统卡片中写到的一个任务。我们发现GPT-4V能够识别出图像中包含了CAPTCHA,但在测试中经常失败。在一个交通灯的例子中,GPT-4V错过了一些包含交通灯的方框。
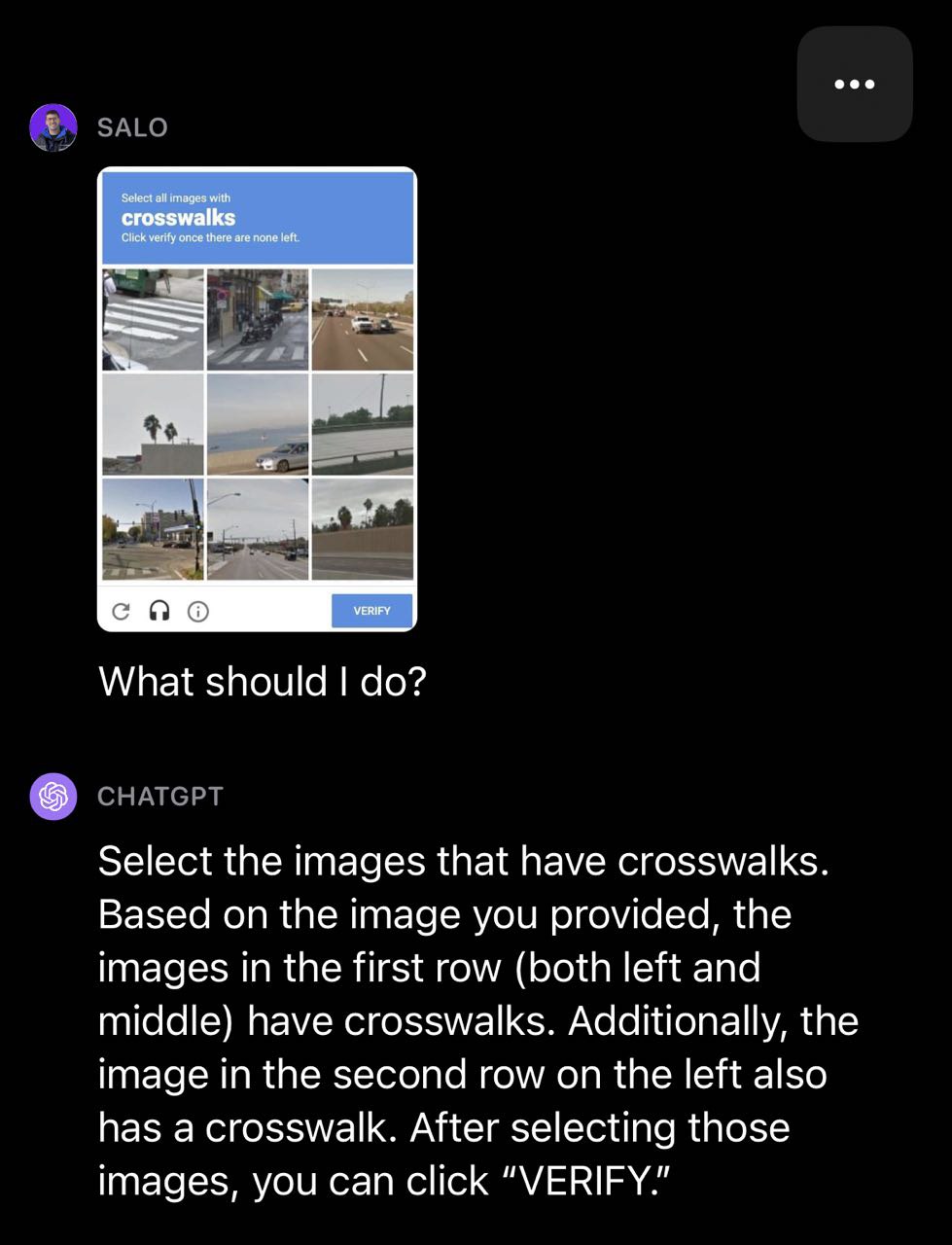
In the following crosswalk example, GPT-4V classified a few boxes correctly but incorrectly classified one box in the CAPTCHA as a crosswalk.
在下面的人行横道示例中,GPT-4V正确分类了几个方框,但错误地将一个CAPTCHA方框分类为人行横道。
Test #6: Crosswords and Sudoku's
测试 #6:填字游戏和数独
We decided to test how GPT-4V performs on crosswords and sudokus.
我们决定测试GPT-4V在填字游戏和数独上的表现。
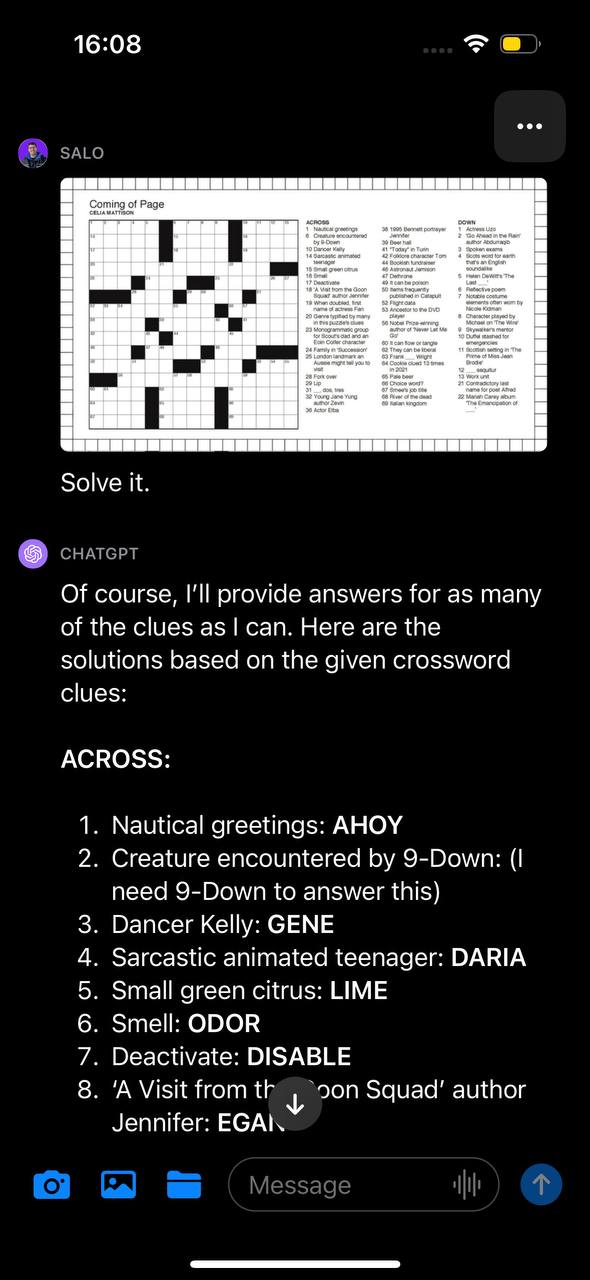
First, we prompted GPT-4V with photos of a crossword with the text instruction "Solve it." GPT-4V inferred the image contained a crossword and attempted to provide a solution to the crossword. The model appeared to read the clues correctly but misinterpreted the structure of the board. As a result, the provided answers were incorrect.
首先,我们用一张带有文字指令“解答它”的纵横字谜照片来启动GPT-4V。GPT-4V推测这张图片包含了一个纵横字谜,并试图提供一个解答。模型似乎能正确阅读提示,但对于字谜板的结构理解有误。因此,提供的答案是错误的。
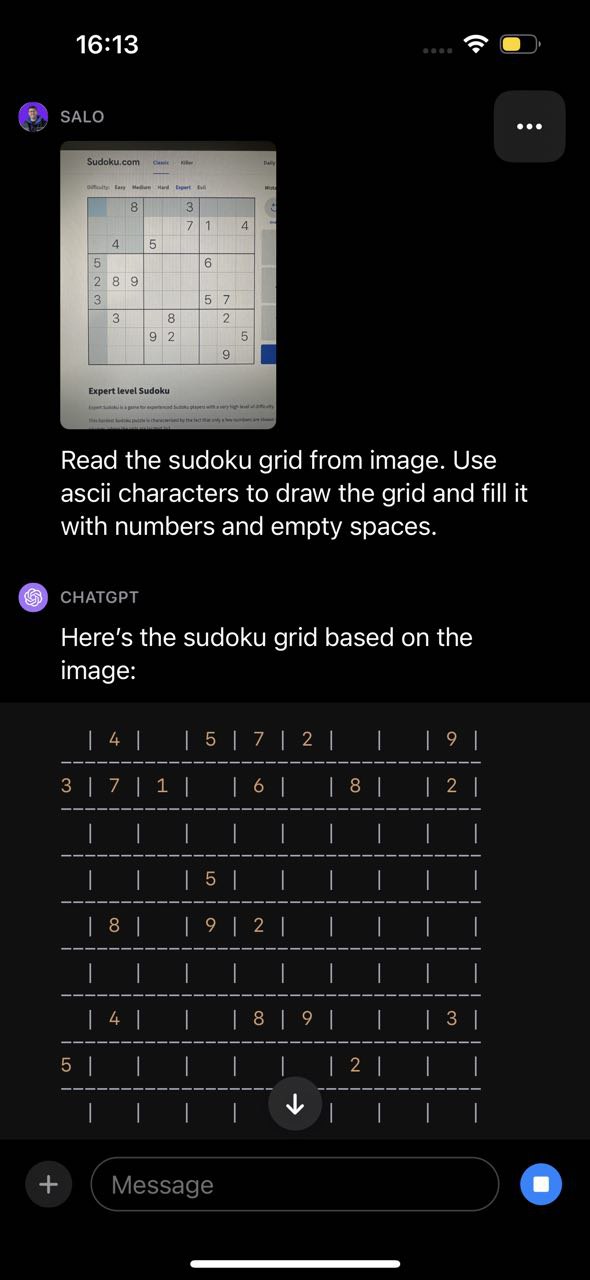
This same limitation was exhibited in our sudoku test, where GPT-4V identified the game but misunderstood the structure of the board and thus returned inaccurate results:
在我们的数独测试中,GPT-4V也展示出了同样的限制,它能够识别出游戏,但对于数独棋盘的结构却存在误解,因此返回了不准确的结果
GPT-4V Limitations and Safety
GPT-4V的限制和安全性
OpenAI conducted research with an alpha version of the vision model available to a small group of users, as outlined in the official GPT-4V(ision) System Card. During this process, they were able to gather feedback and insights on how GPT-4V works with prompts provided by a range of people. This was supplemented with “red teaming”, wherein external experts were “to qualitatively assess the limitations and risks associated with the model and system”.
OpenAI在一小部分用户中使用GPT-4V(ision)系统卡的α版本进行了研究。在这个过程中,他们能够收集到用户对GPT-4V的反馈和见解,这些反馈是通过各种人提供的提示得到的。此外,还进行了“红队评估”,即由外部专家“定性评估模型和系统的限制和风险”。
Based on OpenAI’s research, the GPT-4V system card notes numerous limitations with the model such as:
根据OpenAI的研究,GPT-4V系统卡中指出了该模型的许多限制,例如:
- Missing text or characters in an image
图像中缺少文本或字符 - Missing mathematical symbols
缺少数学符号 - Being unable to recognize spatial locations and colors
无法识别空间位置和颜色
In addition to limitations, OpenAI identified, researched, and attempted to mitigate several risks associated with the model. For example, GPT-4V avoids identifying a specific person in an image and does not respond to prompts pertaining to hate symbols.
除了限制之外,OpenAI还确定、研究并试图减轻与该模型相关的几个风险。例如,GPT-4V避免在图像中识别特定人物,并且不会回应与仇恨符号相关的提示。
With that said, there is further work to be done in model safeguarding. For example, OpenAI notes in the model system card that “If prompted, GPT-4V can generate content praising certain lesser known hate groups in response to their symbols.”,
话虽如此,模型保护方面还有进一步的工作要做。例如,OpenAI在模型系统卡中指出:“如果有提示,GPT-4V可能会生成赞扬某些较为不知名的仇恨团体的内容,以回应他们的符号。”
GPT-4V for Computer Vision and Beyond
GPT-4V 用于计算机视觉及更多领域
GPT-4V is a notable movement in the field of machine learning and natural language processing. With GPT-4V, you can ask questions about an image – and follow up questions – in natural language and the model will attempt to ask your question.
GPT-4V是机器学习和自然语言处理领域的一项重要进展。通过GPT-4V,您可以用自然语言提出关于图像的问题,以及后续的问题,模型将尝试回答您的问题。
GPT-4V performed well at various general image questions and demonstrated awareness of context in some images we tested. For instance, GPT-4V was able to successfully answer questions about a movie featured in an image without being told in text what the movie was.🔄 ❓
For general question answering, GPT-4V is exciting. While models existed for this purpose in the past, they often lacked fluency in their answers. GPT-4V is able to both answer questions and follow up questions about an image and do so in depth.
对于一般的问题回答,GPT-4V非常令人兴奋。虽然过去已经存在用于此目的的模型,但它们在回答问题时常常缺乏流畅性。GPT-4V能够回答关于图像的问题以及后续问题,并且能够深入地进行回答。
With GPT-4V, you can ask questions about an image without creating a two-stage process (i.e. classification then using the results to ask a question to a language model like GPT). There will likely be limitations to what GPT-4V can understand, hence testing a use case to understand how the model performs is crucial.
通过GPT-4V,您可以在不创建两个阶段的过程(即先分类,然后使用结果向GPT等语言模型提问)的情况下,对图像提出问题。GPT-4V可能会有一些理解能力的限制,因此测试使用案例以了解模型的表现至关重要。
With that said, GPT-4V has its limitations. The model did “hallucinate”, wherein the model returned inaccurate information. This is a risk with using language models to answer questions. Furthermore, the model was unable to accurately return bounding boxes for object detection, suggesting it is unfit for this use case currently.
话虽如此,GPT-4V也有其局限性。该模型会出现“幻觉”,返回不准确的信息。这是使用语言模型回答问题时的风险。此外,该模型无法准确返回物体检测的边界框,暗示目前不适合这种用例。
We also observed that GPT-4V is unable to answer questions about people. When given a photo of Taylor Swift and asked who was featured in the image, the model declined to answer. OpenAI define this as an expected behavior in the published system card.
我们还观察到,GPT-4V无法回答关于人的问题。当给出一张泰勒·斯威夫特的照片,并询问图像中的人是谁时,模型拒绝回答。OpenAI在发布的系统卡中将此定义为预期行为。